CLIJ
GPU-accelerated image processing in ImageJ using CLIJ
CLIJ - GPU-accelerated image processing in ImageJ macro
Image processing in modern GPUs allows for accelerating processing speeds massively. This page introduces how to do image processing in the graphics processing unit (GPU) using OpenCL from ImageJ macro inside Fiji using the CLIJ library. It is not necessary to learn OpenCL itself. Preprogrammed routines are supposed to do GPU image processing for you with given ImageJ macro programming experience. The list of preprogrammed routines might be extended depending on the communities needs.
This is how your code might look like if you do GPU based image processing in ImageJ macro:
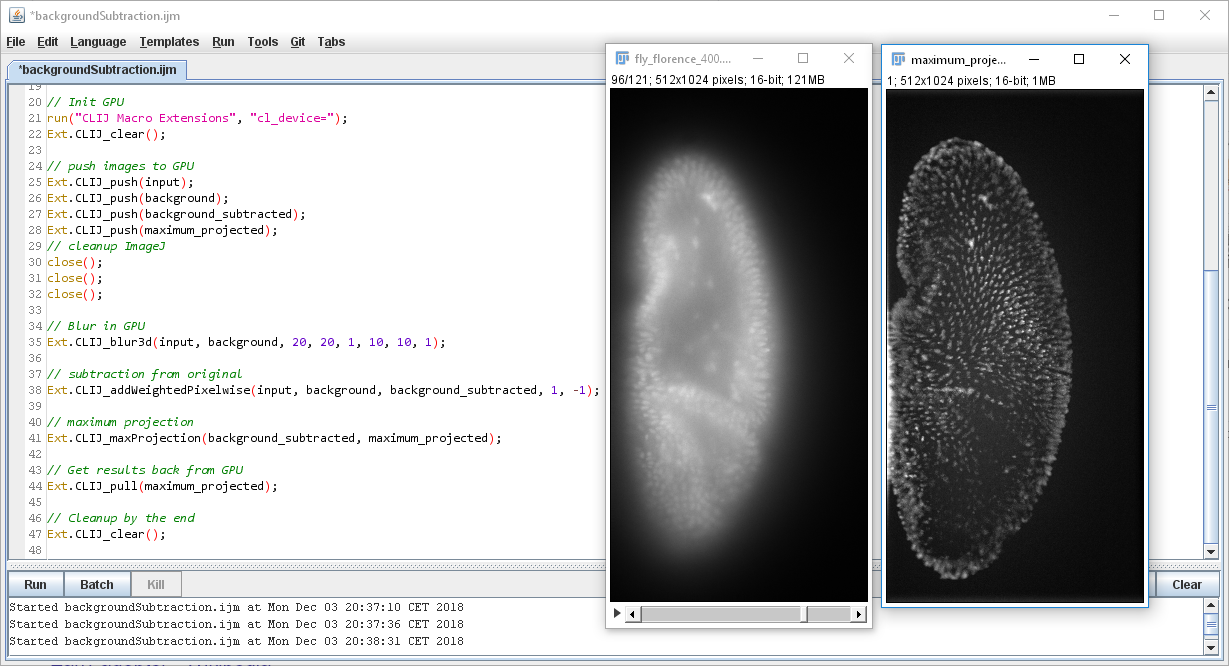
Installation
Follow the installation instructions;
Activating CLIJs macro extensions
To get started, all ImageJ macros using CLIJ have a line like this at the beginning:
run("CLIJ Macro Extensions", "cl_device=");
Note: This line may contain the specific name for a GPU.
You can - but you don’t have to - specify one.
If none is specified, the system will take the first one found.
If you don’t have the named GPU in your computer, another one will be chosen.
You don’t have to enter the full name, you can also just specify a part of the name.
In order to run on any HD named GPU, change the macro like this:
run("CLIJ Macro Extensions", "cl_device=HD");
Transferring images between ImageJ and the GPU
In order to allow images to be processed by the GPU, you need to transfer them into the memory of the GPU.
In order to view images which were processed by the GPU, you need to transfer them back to ImageJ.
The two methods for doing this are called push(image) and pull(image).
You can remove a single image from the GPUs memory by using the release(image) method.
Finally, you can remove all images from the GPU with the clear() method.
In case the destination image doesn’t exist, it will be created automatically in the GPU.
Just push an image A to the GPU, process it with destination B and afterwards, you can pull B back from the GPU to ImageJ in order to show it.
Let’s have a look at an example which loads an image and blurs it using the push-pull mechanism.
// Get test data
run("T1 Head (2.4M, 16-bits)");
input = getTitle();
getDimensions(width, height, channels, slices, frames);
// define under which name the result should be saved
blurred = "Blurred";
// Init GPU
run("CLIJ Macro Extensions", "cl_device=");
Ext.CLIJ_clear();
// push images to GPU
Ext.CLIJ_push(input);
// cleanup ImageJ
run("Close All");
// Blur in GPU
Ext.CLIJ_blur3D(input, blurred, 10, 10, 1);
// Get results back from GPU
Ext.CLIJ_pull(blurred);
// Cleanup by the end
Ext.CLIJ_clear();
To find out, which images are currently stored in the GPU, run the Ext.CLIJ_reportMemory(); method.
Sparing time with GPU based image processing
The overall goal for processing images in the GPU is sparing time. GPUs can process images faster because they can calculate pixel values of many pixels in parallel. Furthermore, images in memory of modern GPUs can be accessed faster than in ImageJ. However, there is a drawback: pushing/pulling the images to/from the GPU takes time. Thus, overall efficiency can only be achieved if whole pipelines are processed in the GPU. Furthermore, repeatedly using the same operations on a GPU pays off because operations are cached. Reusing them is faster than using other methods.
Let’s compare the Mean 3D filter of ImageJ with it’s counterpart in CLIJ.
The example macro is benchmarking.ijm.
It executes both operations ten times and measures the time each operation takes.
This is just an excerpt of the macro:
// Local mean filter in CPU
for (i = 1; i <= 10; i++) {
time = getTime();
run("Mean 3D...", "x=3 y=3 z=3");
print("CPU mean filter no " + i + " took " + (getTime() - time));
}
// push images to GPU
time = getTime();
Ext.CLIJ_push(input);
Ext.CLIJ_push(blurred);
print("Pushing two images to the GPU took " + (getTime() - time) + " msec");
// Local mean filter in GPU
for (i = 1; i <= 10; i++) {
time = getTime();
Ext.CLIJ_mean3DBox(input, blurred, 3, 3, 3);
print("GPU mean filter no " + i + " took " + (getTime() - time));
}
// Get results back from GPU
time = getTime();
Ext.CLIJ_pull(blurred);
print("Pullning one image from the GPU took " + (getTime() - time) + " msec");
When executing the macro on an Intel Core i7-8565U CPU with a built-in Intel UHD Graphics 620 GPU (Windows 10, 64 bit), the output is:
CPU mean filter no 1 took 3907 msec
CPU mean filter no 2 took 3664 msec
CPU mean filter no 3 took 3569 msec
CPU mean filter no 4 took 3414 msec
CPU mean filter no 5 took 2325 msec
CPU mean filter no 6 took 2752 msec
CPU mean filter no 7 took 2395 msec
CPU mean filter no 8 took 2633 msec
CPU mean filter no 9 took 2543 msec
CPU mean filter no 10 took 2610 msec
Pushing one image to the GPU took 11 msec
GPU mean filter no 1 took 489 msec
GPU mean filter no 2 took 27 msec
GPU mean filter no 3 took 27 msec
GPU mean filter no 4 took 28 msec
GPU mean filter no 5 took 29 msec
GPU mean filter no 6 took 39 msec
GPU mean filter no 7 took 34 msec
GPU mean filter no 8 took 29 msec
GPU mean filter no 9 took 30 msec
GPU mean filter no 10 took 31 msec
Pulling one image from the GPU took 47 msec
Thus, on the CPU it takes 30 seconds, while using the GPU it just takes 0.8 seconds. Let’s execute it again.
CPU mean filter no 1 took 2254 msec
CPU mean filter no 2 took 2187 msec
CPU mean filter no 3 took 2264 msec
CPU mean filter no 4 took 2491 msec
CPU mean filter no 5 took 2915 msec
CPU mean filter no 6 took 2299 msec
CPU mean filter no 7 took 2401 msec
CPU mean filter no 8 took 2441 msec
CPU mean filter no 9 took 2493 msec
CPU mean filter no 10 took 2588 msec
Pushing one image to the GPU took 9 msec
GPU mean filter no 1 took 30 msec
GPU mean filter no 2 took 28 msec
GPU mean filter no 3 took 30 msec
GPU mean filter no 4 took 39 msec
GPU mean filter no 5 took 34 msec
GPU mean filter no 6 took 34 msec
GPU mean filter no 7 took 34 msec
GPU mean filter no 8 took 32 msec
GPU mean filter no 9 took 40 msec
GPU mean filter no 10 took 32 msec
Pulling one image from the GPU took 43 msec
On the CPU it still takes 24 seconds, while using the GPU it goes down to 0.4 seconds. The additional speedup comes from the caching mechanism mentioned above.
Heureka, we can spare 90% of the time by executing the operation on the GPU! And this works on a small laptop without dedicated GPU. This example should just motivate you to test your workflow on a GPU and guide you how to evaluate its performance.
Side note: ImageJs mean filter runs inplace. That means the result is stored in the same memory as the input image. With every iteration in the for loop, the image becomes more and more blurry. The OpenCL operation in the GPU always starts from the input image and puts its result in the blurred image. Thus, the resulting images will look different. Be a sceptical scietist when processing images in the GPU. Check that the workflow is indeed doing the right thing. This is especially important when working with experimental software.
This is the view on results from the mean filter on CPU and GPU together with the difference image of both:
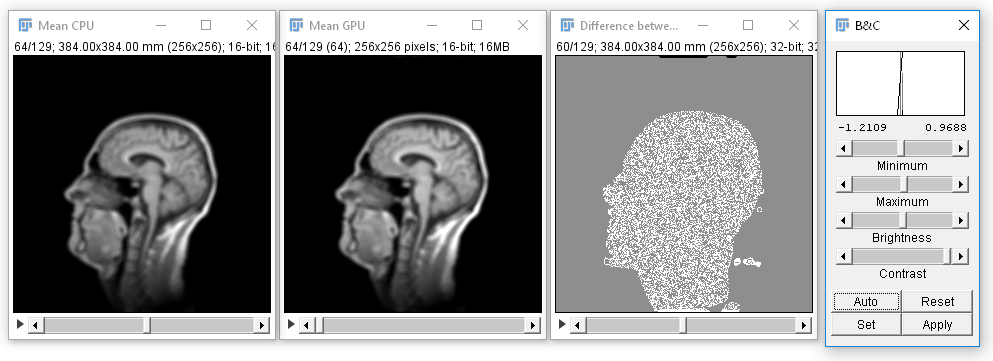
In presented case, have a look at mean.ijm to see how different the results from CPU and GPU actually are. In some of the filters, I observed small differences between ImageJ and OpenCL especially at the borders of the images. This is related to the fact that CLIJ contains new implementations of operations in ImageJ. There is a large number of unit tests in the library, ensuring these differences are small and in case they appear, they mostly influence image borders.